머신러닝이란 데이터에 대한 학습을 수행하는 알고리즘에 대한 학문입니다.
데이터 x가 있다고 할 때 이것을 함수 f 에 넘기면 데이터 x의 예측값 혹은 x를 추론하거나 이해하는 데 도움이 되는 좀 더 압축된 x의 표현을 아웃풋으로 내보냅니다. 이 함수 f에 대한 탐구, f의 최적화 등이 머신러닝의 주요 주제입니다.

머신러닝을 사용해 문제를 해결하기 전 지도(Supervised) 혹은 비지도(Unsupervised) 알고리즘을 적용해야 하는 문제인지 분류할 수 있습니다.
1. Supervised learning
지도학습(Supervised learning; 지도 알고리즘)은 알고리즘의 트레이닝을 수행할 때 라벨에 대한 정보를 일부 제공할 때를 의미합니다.
알고리즘은 x와 y 사이의 mapping(f(x))을 트레이닝하게 되어 있습니다.
트레이닝 이후에는 추론(Inference) 과정을 진행하게 됩니다. 트레이닝 과정에서 사용되지 않은 '테스트 데이터'를 사용하며, 추론 과정의 목적은 알고리즘이 전혀 보지 못했던 데이터 x를 가지고 이것에 해당하는 레이블을 미리 주어진 트레이닝 셋의 패턴에 따라 추측하는 것입니다.
지도학습은 이진(Binary) 혹은 다계층(Multi class) 분류를 하는지에 따라 추가로 분류할 수 있습니다.
이진의 경우 y가 0 또는 1이 되어야 합니다. 예를 들어서 어떤 이메일 y에 대해서 값이 0이면 스팸 메일, 1이면 스팸이 아닌 메일로 나타낼 수 있습니다.
이 경우에는 일단 트레이닝 데이터 세트를 준비하는데, (xi, yi)의 튜플 N개를 제공합니다.
그럼 우리는 트레이닝 세트에 레이블값들을 가지고 있게 됩니다. 그런데... 이것은 어디에서 제공할까요?
실제로는 사람이 데이터를 하나하나 보면서, 데이터 항목마다 0 또는 1, 혹은 1~k의 클래스 레이블을 배정하여 만들어야 합니다.(전자의 경우 이진, 후자의 경우 다계층)
스팸메일의 예시에서 추론 과정에서는 데이터 x만 관측했을 때 레이블을 0또는 1로 예측하는 것이 임무입니다.
즉 이메일 xi가 스팸인지 아닌지를 판별하는 것이 목적입니다.
다계층 분류의 경우 레이블 값이 1에서 k까지 있습니다.
예를 들어 x가 이미지로 주어지고 y가 1 = 강아지의 이미지, 2 = 고양이의 의미지, 3 = 새의 이미지 . . . 와 같이 둘 수 있습니다. k는 이미지 x가 가질 수 있는 레이블의 가짓수가 되며 주어진 이미지 xi가 어떤 이미지인지 판별하는 것이 목적입니다.
여기까지가 분류(Classification)할 때의 세팅입니다.
회귀(Regression)에서는 데이터 x를 가지고 있을 때 이것을 바탕으로 y를 찾는것을 말하며 이때 y가 R^d(d차원 벡터)에 있습니다.
예를 들어 x는 1일 차의 어느 회사 x의 주식, y는 2일 차의 주식으로 둘 수 있습니다. 이 때 주목할 점은 y가 굳이 스칼라 값이 아니어도 되고 d차원 벡터여도 상관 없습니다.
차이점이라면 이젠 예측값이 더이상 분류의 성격을 지니고 있지 않는다는 점입니다.
다른 종류로는 Sequence annotation이 있습니다.
x1, . . . , xn 까지 n개의 수열이 있을 때 이에 대응되는 적당한 y1, . . . , ym m개의 수열을 찾는 것이 목표입니다.
이때 n과 m이 굳이 같아야 할 필요는 없습니다. 즉 n개의 아이템이 주어졌을 때 m개의 아이템을 출력해야 하는데 같은 개수가 아니어도 된다는 겁니다.
번역을 예로 들어봅시다. x의 수열이 주어져 있고, 이 수열이 영어 문장을 나타낸다고 생각합시다.
"I am a boy" 라는 문장은 x1 = I, x2 = am, x3 = a, x4 = boy 라고 줄 수 있습니다. 각 x는 하나의 영어 단어에 해당하고 y는 그것의 번역 결과를 나타냅니다.
y가 "나는 소년이다"라고 번역된다면 y1 = 나, y2 = 는, y3 = 소년, y4 = 이다 가 되겠지요.
이것이 Sequence annotation입니다.
예측(Prediction) 에서는 x_t와 y_1에서 y_t-1 까지 데이터가 제공됩니다. 다른 말로는 각 시각 t마다 그 이전의 레이블 y_1에서 y_t-1 까지를 받아 y_t를 아웃풋으로 내보내는 것입니다.
가장 확실한 예로는, 센서를 통해 비행기를 추적하고 있다고 합시다.
x_t는 노이즈가 섞인 센서의 값을, y_1 ~ y_t-1는 시간 t-1까지의 비행기의 위치를 나타냅니다.
이 때 우리는 예전 위치들과 현재의 센서값을 통해 비행기의 현재 위치(t에서의 위치)를 추측해야 합니다.
이것을 tracking problem이라고 부르고, prediction problem에 속해 있습니다.
2. Unsupervised learning
비지도학습(unsupervised learning)에서는 데이터를 레이블링해주는 주체가 따로 없습니다. 즉 트레이닝이 일어나는 중에 레이블에 대한 정보가 전혀 없다는 뜻입니다.
비지도학습의 한 종류로는 클러스터링(Clustering)이 있습니다.
여기서는 데이터를 나타내는 Cluster centroid의 Prototype을 찾는 것이 목표입니다. (Find a set of prototypes representing the data)
그 일환으로 k-mean clustering 알고리즘이 있습니다.
k-means 클러스터링은 데이터의 셋이 있을 때 데이터를 K개씩 그룹을 짓는 것입니다. 이때 각 클러스터의 centroid를 k-centroid라고 부릅니다.
Sequence Analysis는 관찰값의 latent casual sequence 를 찾습니다. 이것의 예로는 Hidden Markov Model, Gaussian assumption을 따르는 칼만 필터(Kalman Filter)가 있습니다.
그 다음으로는 Independent component, 혹은 Dictionary learning이라는 게 있는데, 이것은 주어진 관찰값에 대해서 factor들을 찾아야 합니다. (Find a set of factors for observation)
이것 외에 novelty detection이라는 것도 있는데, one class SVM 문제라고도 불립니다.
여기서는 정상적인 데이터의 셋이 있을 때, 이 중에서 정상과는 매우 다르게 보이는 novel point들의 셋을 찾는 것이 목적입니다.
즉 이 테크닉을 부정행위 탐지와 같은 곳에 적용할 수 있을 것입니다.
또 Independent component analysis가 있습니다. 여러 개의 음원에서 소음이 나고 있어, 이것들이 모두 하나의 파형을 나타내는 파일로 녹음되어 있다고 가정합니다. 즉 예를 들어 MP3 파일 하나에 온갖 종류의 소음들 : 경찰차 소리, 누군가의 연설, 밴드의 연주, 아기의 울음소리, TV 소리, 피아노 소리 등등이 들어가 있다고 합시다.
이것들이 모두 하나의 파형으로 합쳐져 MP3 파일 하나에 들어가 있을 때, 해야 하는 작업은 특정 주파수가 어떤 사람이나 물체에 해당하는지에 대한 레이블 정보를 가지고 있지 않을 때, 하나의 waveform 파일을 서로 다른 음원에서 나온 소리를 가진 K개의 다른 파일로 쪼개는 작업을 자동으로 해야 합니다.
이 경우에는 6개의 특성 있는 음원이 존재하는데, 여기서 우리는 자동으로 이 음원들을 찾거나 각 음원에 해당하는 것을 파일로 분리해야 합니다.
이것을 independent component analysis라고 부릅니다.

여기서 알고리즘 적으로 확실하지 않는 것 중 하나는 이 정보를 모두 분리해야 하는데, 총 몇 종류의 근원이 있는지, 혹은 몇 개의 요인이 있는지 어떻게 알 수 있을까요? 이것만으로도 굉장히 어려운 문제가 되는데, 몇 종류의 베리에이션 (variation)이 있는지를 알아도 알고리즘이 그리 강력하지 못합니다. 정말로 매우 어려운 문제이기 때문이죠.
그다음에는 Normalized Cuts를 살펴봅시다. 이것은 clustering algorithm의 변형입니다. 예를 들어서 이 경우에는 위에 있는 이미지들에 우리에게 제공되었을 때, 우리는 아래와 같은 예측을 하고 싶습니다. 사진의 각 픽셀을 의미 있는 레이블을 할당해야 합니다.

예를 들어 위 예시의 왼쪽 사진에서 남자가 입고 있는 옷에 대해 같은 색깔에 해당하는 픽셀들을 모두 레이블링해야 한다는 말입니다. 그런 다음 하늘에 해당하는 픽셀들을 같은 색으로 레이블링해야 합니다.
즉 이건 각 영역으로 추측을 해야 하고, 이것을 픽셀 레이블에 대한 정보 없이 수행해야 합니다. 이것도 매우 어려운 문제입니다. 여기서도 같은 문제를 제기할 수 있는데, 한 이미지 내에 몇 개의 다른 객체들, 혹은 구분이 가능한 물체들이 있을까요?
비지도학습의 다른 예시로 주성분 분석(principal component analysis)가 있습니다. 여기서는 레이블이 주어져 있지 않을 때, 우리는 principal component 중에서 가장 크게 변화하는 축을 찾아야 합니다.
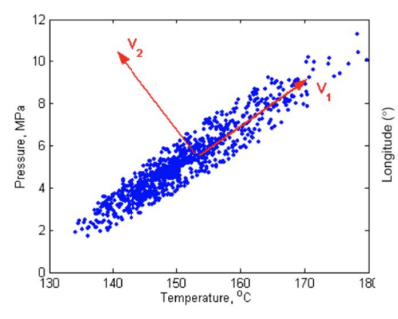
이 축들은 공분산(covariance;공변) 행렬의 고유벡터들(eigenvectors)에 대응됩니다.
예를 들어 위 데이터는 온도와 압력에 대한 데이터인데, 여기서 우리는 데이터의 분산된 정도를 가장 잘 나타내는 축들을 찾아야 합니다.
물론 첫 번째 축은 여기의 차원에 해당합니다. 이건 첫 번째 principal component에 해당하고, 저건 두 번째 principal component에 해당합니다. 즉 이것을 데이터 압축 (data compression)에 활용할 수 있는데, 데이터를 처음 k개의 principal axes에 투영(Projection)하면 됩니다. 물론 여기서 k는 데이터의 마지막 차원을 나타냅니다.
즉 데이터의 차원이 n이고, 처음 k개의 principal component들을 가져오면, 데이터를 k개의 principal component들에 투영시킴으로써 데이터의 압축을 수행할 수 있습니다.
이렇게 dimensionality reduction을 할 수 있습니다. 결괏값으로는 데이터와 차원을 나타내는 k를 얻게 됩니다.
'개발 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 딥러닝의 개념 / 딥러닝 과정 / 신경망 구조 / 순전파, 역전파 (0) | 2023.02.07 |
|---|---|
| [머신러닝] 신호, 파이프라인 (0) | 2022.10.13 |
| [머신러닝] 공개 데이터셋 저장소 (0) | 2022.10.12 |
| [머신러닝] 머신러닝이란? (2) | 2022.10.07 |