머신러닝에서는 일반화 성능을 향상시키는 것 즉 테스트 오류를 최소화하는 것이 주된 목표입니다.
Cross validation은 validation set을 여러 개 뽑아 각각에 대한 validation error를 추출해 그것의 평균이 가장 작도록 하는 모델을 찾아나가는 것입니다.
용어 정리
1. Overfitting(과적합)
: 학습 정확도는 상당히 높은 반면 실제 테스트시 정확도가 상당히 떨어지는 문제
학습을 위한 데이터는 한정적이기 때문에 학습 정확도가 100%가 되더라도 새롭게 주어지는 테스트 샘플에 대한 정확도는 제법 괴리가 있을 수 있다는 것. Decision tree에서 Depth 즉 트리의 길이를 최대한으로 하였을 때 학습 성능은 100%가 되지만 계산량이 늘어나는 문제와 과하게 학습 데이터에 최적화된다는 문제를 의미합니다.
2. IID assumption
: Independent and Identically Distributed 의 약자로, 기본적으로 학습 데이터와 테스트 데이터가 같은 분포 즉 동일한 샘플 분포에서 왔다는 가정입니다. 즉 데이터와 데이터 추출 방식이 독립적이어야 한다는 말입니다.
(1) IID 가정의 예시
: 카드 더미에서 카드들을 뽑는 예시를 들 수 있습니다. 카드 더미에서 카드를 하나 뽑아 확인해 학습 데이터에 추가한 다음 다시 카드 뭉치에 넣습니다. 더미를 다시 섞은 다음 또 다른 카드를 두 번째로 뽑는데 이번에는 이것을 테스트 데이터에 추가합니다. 이 경우 학습 데이터와 테스트 데이터가 서로 IID 관계에 있다고 얘기할 수 있습니다.
왜냐하면 전에 뽑았던 데이터 샘플이 이후에 뽑는 샘플에 영향을 전혀 미치지 않기 때문입니다.(복원추출 + 랜덤화) 카드를 다시 넣는 행위와 더미를 섞는 행위가 데이터의 독립성과 샘플 분포의 동일성을 보증한다고 볼 수 있습니다.
(2) IID가 이뤄지지 않는 경우
: 카드를 한 장 뽑고 카드 더미에 넣는데 카드 더미의 가장 아래에 넣는 경우를 생각해봅시다. 그리고 셔플을 하지 않고 데이터 추출과정을 계속 반복해 나갑니다. 이 경우 셔플이 이루어지지 않았기에 랜덤성이 사라집니다. 즉 순서가 고정되어버립니다. 항상 똑같은 샘플이 학습데이터와 테스트 데이터에 들어가기 때문에 학습 데이터와 테스트 데이터가 상관관계를 가질 수 있게 되어버립니다.
이것은 서로 독립되어 있는 관계가 아니기 때문에 IID 가정이 깨지게 되는 예시입니다.
더 간단한 예시는 카드를 뽑은 다음에 셔플을 하긴 하지만 카드를 다시 넣지는 않는 것입니다. 그럼 카드 더미가 점점 줄어들기 때문에 같은 데이터, 즉 같은 샘플 분포에서 카드를 뽑는 것이 아니기 때문에 테스트 데이터와 트레이닝 데이터가 서로 IDD 관계에 있다고 볼 수 없게 되는 겁니다.
3. Training error(학습 오류)
: 학습 오류가 작을 수록 과적합 정도가 커집니다. 즉 최대한으로 나눈 decision tree(의사결정 나무)는 과적합이 더 심하게 발생한다는 것입니다. 반대로 split node를 2~3개 정도로 제한을 걸었다면 의사결정 나무는 과적합이 덜 발생합니다. 학습 데이터 자체는 많을 수록 좋지만 학습 오류는 작을 수록 무조건적으로 좋은 것이 아니라는 뜻입니다.
4. Validation error
: 학습 데이터와 테스트 데이터 외에 validation data라는 것을 구성합니다. 기존에 있던 학습 데이터를 두 개로 나누는 것이며 두 개 중 하나는 학습에, 나머지 하나를 validation set이라고 구성하고 이것에 대해 가상에 가상의 테스트셋을 구성합니다. 즉 가상 트레이닝을 한다고 볼 수 있습니다. IID 가정이 있기에 유효한 방법.
트레이닝 데이터와 학습 데이터, 테스트 데이터 모두 결국 같은 분포에서 추출했기 때문에 학습 데이터에서 일부분을 샘플링한 것 역시 테스트 데이터로 예상되는 것과 비슷한 분포를 갖추게 됩니다. 그래서 밸리데이션 셋을 테스트 셋과 비슷하다고 생각하고 일반화 성능을 예측하게 됩니다. 학습 데이터에서 일부분을 추출했기 때문에 발생하는 에러를 validation error라 합니다.
이때 첫 번째로 뽑은 밸리데이션이 80% 성능, 두 번째에서 70%의 성능을 보이는 등 성능의 차이가 존재할 수밖에 없습니다. 결국에 샘플들의 모임이기 때문에 이러한 문제가 발생하는데 유효성을 높이기 위해 크로스 밸리데이션이라는 방법론을 사용하게 됩니다.
N-fold cross validation
N 가지 종류의 학습데이터와 N 가지 밸리데이션 셋 모임으로 나눕니다. 이때 각각의 모임을 폴드라고 정의합니다.(N개의 fold) 각각의 폴드에 대해서 트레인 셋(학습 데이터)도 바뀌고 밸리데이션 셋도 바뀌니까 각 밸리데이션 셋이 대해 머신러닝 모델의 성능이 다르게 나옵니다. 이때 얻어진 서로 다른 밸리데이션 에러 값들을 평균을 낸 다음 그 평균이 가장 작도록 하는 모델을 찾아나가는 것이 크로스 밸리데이션 방법론입니다.
3-fold cross validation을 살펴보겠습니다.
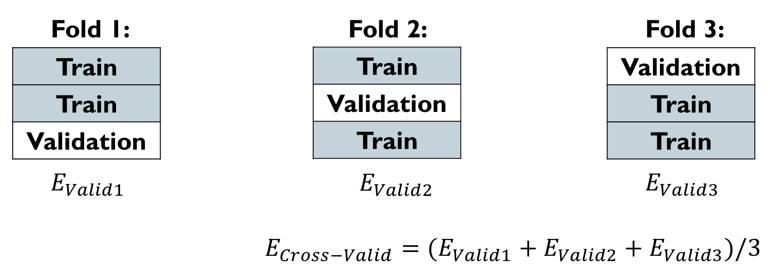
주어진 학습 데이터를 3등분 한 다음 총 세 번의 머신러닝 모델 학습을 수행합니다. 3개로 나눈 것 중에 한 개만 밸리데이션 셋으로 활용한다면 총 3가지 종류의 학습데이터와 3가지 밸리데이션 셋 모임으로 나뉘게 됩니다. 이 각각의 모임을 fold라고 합니다. 3가지 폴드에 대해서 각각의 validation error를 구한 것을 e1, e2, e3라 했을 때 cross validation error는 에러들의 평균입니다.
이 방법론의 목표는 서로 다른 Validation 오류 값들의 평균을 가장 작게 하는 모델을 찾아나가는 것입니다. 가장 일반적으로 사용되는 방법.
물론 여러 번 머신러닝 기법을 적용해야 하기 때문에 시간이 더 걸린다는 단점또한 존재합니다만(3, 5 fold가 일반적이며 단순계산으로는 계산량이 3, 5배가 됨) 테스트 데이터를 미리 볼 필요 없이 테스트 데이터에서 성능과 가장 유사한 성능을 볼 수 있다는 점에서 직관적이라는 장점이 있습니다.
Parameter VS Hyper-parameter
파라미터의 경우 트레이닝 알고리즘을 통해서 얻어진 값으로 우리가 어떻게 할 수 있는 변수를 말하지 않습니다. 정해놓은 학습 기법을 통해 출력되고 있는 값이 파라미터가 되겠습니다.
하이퍼 파라미터는 학습 전에 사용자가 정해줄 수 있는 값입니다. 결국 모든 머신러닝 기법에서 바꿀 수 있는 건 하이퍼 파라미터입니다.
앞서 얘기했던 크로스 밸리데이션 에러를 기준으로 하이퍼 파라미터를 조금씩 바꿔가면서 크로스 밸리데이션 에러가 가장 작아지는 하이퍼 파라미터를 찾으면 됩니다. 크로스 밸리데이션 에러가 가장 작다는 것은 일반화 성능이 높아질 수 있다는 얘기가 되구요.

결국 하이퍼 파라미터를 조정하며 밸리데이션 에러가 제일 작은 모델을 일반화 성능이 가장 좋은 모델로 선택하는 것이 머신러닝에서 주된 논의가 됩니다.